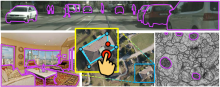
We have developed algorithms that significantly speed up standard annotations for Computer Vision through human-in-the-loop AI models.
Using recurrent and convolutional neural networks, the algorithms assist human annotators through both annotation creation and editing, while simultaneously learning to continuously improve from human assistance.
These state-of-the-art algorithms are fully integrated in the Toronto Annotation Suite (TORAS), a web-based application that allows for larger, more efficient, and more accurate data annotation projects.
TORAS is a web-based AI-powered annotation platform. TORAS provides a repository system that allows efficient data management and collaboration between users. Data annotation can be done in a consistent way with "recipes" which is a blueprint of annotation tasks that define the type of tasks and how an annotator should annotate data. TORAS is equipped with human-in-the-loop AI tools as well as practical editing tools that enable productive data annotation.
The project is led by Prof. Sanja Fidler, an computer vision and AI pioneer whose research interests include 2D and 3D object detection, particularly scalable multi-class detection, object segmentation and image labeling, and (3D) scene understanding. Her work also focuses on the interplay between language and vision: generating sentential descriptions about complex scenes, as well as using textual descriptions for better scene parsing (e.g., in the scenario of the human-robot interaction).
OPPORTUNITY
Modern Machine Learning heavily depends on large scale annotated data, which is still primarily connected through fully manual human labour. Our product significantly outperforms annotation benchmarks in both automatic (10% absolute and 16% relative improvement in mean IoU) and interactive modes (requiring 50% fewer clicks by annotators). In simulated settings, we show a dramatic reduction of >10x number of human clicks required to annotate data to high levels of accuracy.
STATUS
- US patent: US11556797B2 Systems and methods for polygon object annotation and a method of training an object annotation system, along with other jurisdictions
- Licensing options available for commercial use.